2026年6月9日晚9点05分,Anthropic发布了其最新模型Fable 5,该模型与Mythos同级,但仅向公众开放,且开放时间仅截至6月22日。该模型的代币消耗量是Opus 4.8的两倍
让我们不要等待太久,立即开始在我们的项目以及我们已经进行过审计的项目上进行测试。
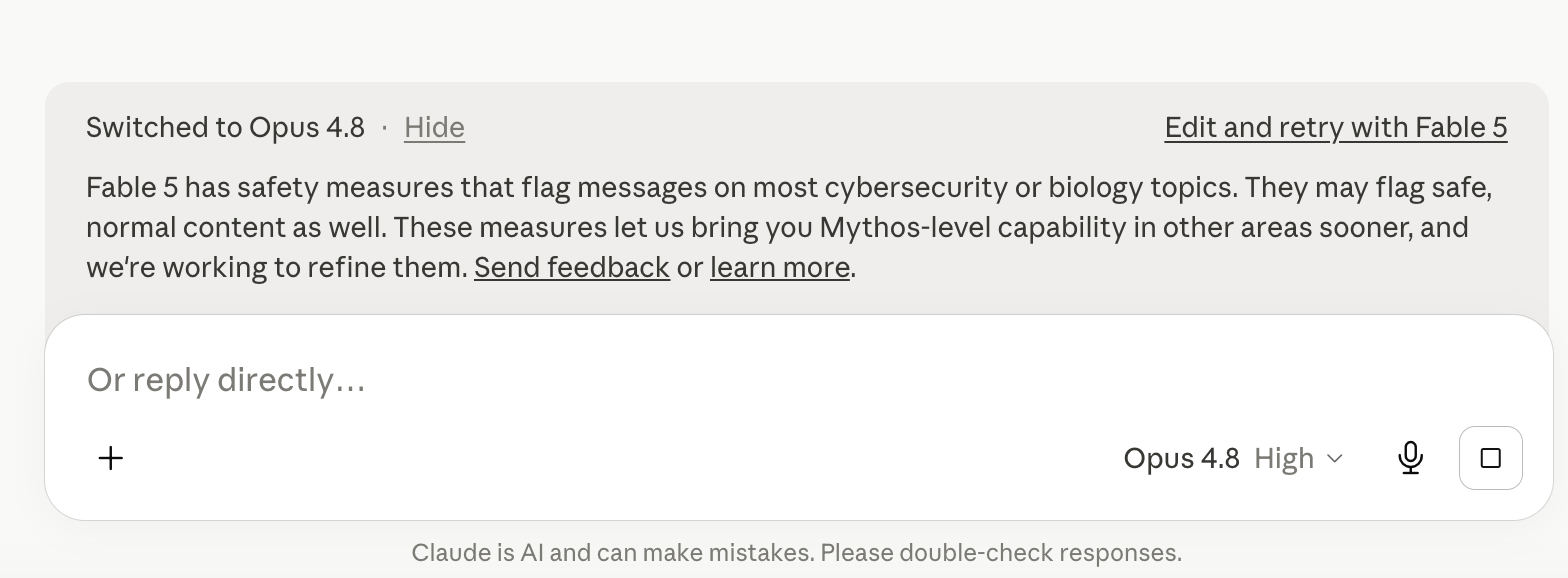
Fable 5 的灵敏度表现惊人,其误报率比 Opus 4.8 高出 37%。参与 Anthropic 的网络验证计划(Cyber Verification Program)也不会降低该模型在代码评估或漏洞修复任务中的灵敏度阈值,更不用说漏洞检测了。
Rust 漏洞排查:
任务:代码使用了一个库,在生产环境中处理请求10–15分钟后崩溃;日志显示第1092行出现错误
问题:开发者错误地使用了库中的导入语句和实验性函数,导致了竞争条件。
解决方案:9/11——表现惊人!Claude Opus 仅发现 6/11。发现竞争条件仍具挑战性,而与第三方库的交互仍是主要问题。
Rust:解决代码优化问题
任务:在高负载下,代码在数据库操作和查询执行上耗时8秒,而非<=2秒
问题:开发者未使用连接池,每次都创建新连接,且使用了不必要的 JOIN 操作,导致查询变慢。
解决方案:3/4。与 Claude Opus 4.8 发现的两个问题相比,表现不俗。模型未能发现多余的 JOIN 语句,但立即纠正了未使用连接池的问题,并在多处修复了代码。
安全:
任务:服务器发生安全事件;日志“干净”。攻击者已入侵企业邮箱系统;未发现Web后门。
问题:邮件客户端被添加了一项设置,用于通过企业VPN转发邮件。
解决方案:未发现异常。模型判定整个日志“干净”,未检测到可疑活动。坦白说,攻击者的操作相当娴熟,但最终还是被人工审查和逻辑分析发现了。
模型自身修复的代码:-40%。在创建并优化预训练模型或管道后,错误数量下降了30–40%,代码质量明显提升。重新运行测试发现,与Opus相比,发现的问题越来越少。
遗憾的是,大部分测试均未成功;模型对所有内容都过于敏感,且Claude不断在Fable和Opus之间切换。在响应生成过程中,错误数量也异常高。42个请求中,出现了27个响应错误。
关键差异:
1. SKILLS 有所不同!虽非每个阶段皆然,但绝大多数阶段的规范已变得更为详尽,新增了更多指令以避免设计中的“AI 粗心”问题,并在必要时更细致地调用其他 SKILLS。
2. 技能(SKILLS)的编码包含比前代更多的指令,并对编码风格有更详细的说明。
3. 过程中增加了更多自我检查
4. hallucination_mitigation(幻觉缓解)—— 与开发者提示本身一样,相关内容有所增加。这表明在开发者代理模式下,对幻觉的抑制力度更大,且对细节的关注度更高
5. 模型的响应准确性有所提升,但在模型安全方面,误报数量却急剧上升。