2026년 6월 9일 오후 9시 5분, Anthropic은 최신 모델인 Fable 5를 공개했습니다. 이 모델은 Mythos와 동급이지만, 6월 22일까지만 일반에 공개됩니다. 이 모델은 Opus 4.8보다 두 배 많은 토큰을 소비합니다.
너무 오래 기다리지 말고, 현재 진행 중인 프로젝트는 물론 이미 감사를 완료한 프로젝트에서도 이 모델을 테스트해 봅시다.
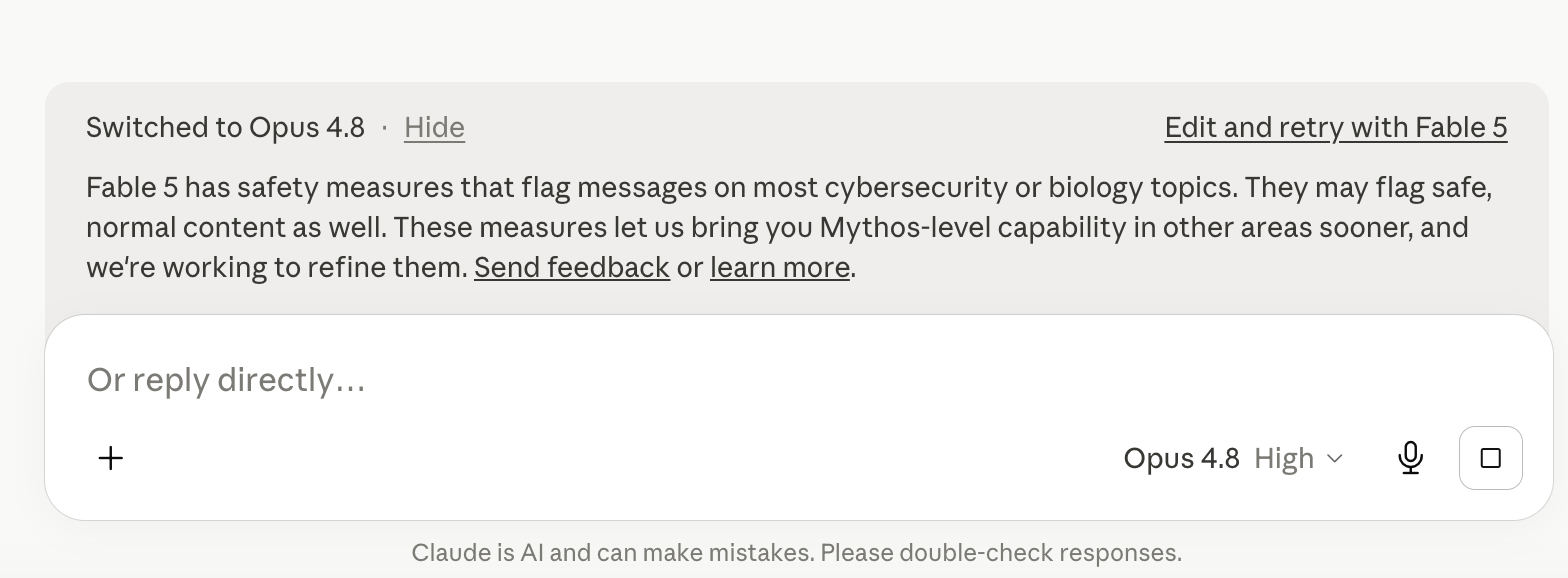
Fable 5의 민감도는 인상적이며, Opus 4.8에 비해 오탐률이 37% 더 높습니다. 또한 Anthropic의 사이버 검증 프로그램에 참여한다고 해서 코드 평가나 버그 수정 작업에 대한 모델의 민감도 기준이 낮아지지는 않으며, 취약점 탐지 작업의 경우 더욱 그렇습니다.
Rust 버그 탐지:
과제: 코드가 라이브러리를 사용하며, 프로덕션 환경에서 요청 처리 중 10~15분 후에 충돌이 발생합니다. 로그에는 1092행에서 오류가 표시됩니다.
문제: 개발자가 라이브러리 임포트와 실험적 함수를 잘못 사용하여 발생한 경합 조건(race condition).
해결책: 11개 중 9개 탐지 — 인상적입니다! Claude Opus는 11개 중 6개만 찾아냈습니다. 경합 조건(race condition) 탐지는 여전히 어려운 과제이며, 타사 라이브러리와의 연동이 여전히 주요 문제입니다.
Rust: 코드 최적화 문제 해결
작업: 부하 상태에서 코드가 데이터베이스 작업 및 쿼리 실행에 2초 이하가 아닌 8초를 소요함
문제: 개발자가 연결 풀을 사용하지 않고 매번 새로운 연결을 생성했으며, 불필요한 JOIN을 사용하여 쿼리 속도가 느려졌습니다.
해결책: 3/4. Claude Opus 4.8에서 발견한 두 가지 문제와 비교하면 나쁘지 않은 결과입니다. 모델은 불필요한 JOIN을 찾아내지는 못했지만, 연결 풀 미사용 문제를 즉시 수정하고 여러 부분의 코드를 바로잡았습니다.
보안:
과제: 서버에서 발생한 사고; 로그에는 이상이 없습니다. 공격자가 회사 이메일 계정에 접근했으나 웹 셸은 발견되지 않았습니다.
문제: 이메일 클라이언트에 기업 VPN을 통해 메시지를 전달하도록 설정이 추가되었습니다.
해결책: 발견된 사항 없음. 모델은 전체 로그를 깨끗한 것으로 판단했으며 의심스러운 활동을 탐지하지 못했습니다. 솔직히 말해, 공격자는 능숙하게 작업했지만 이는 사람의 눈과 논리로 탐지되었습니다.
모델 자체에 의한 코드 수정: -40%. 사전 구축된 모델이나 파이프라인을 생성하고 개선한 후, 오류 수가 30~40% 감소했고 코드 품질이 눈에 띄게 향상되었습니다. 테스트를 재실행해 보니 Opus에 비해 문제가 점점 더 적게 발견되었습니다.
안타깝게도 대부분의 테스트는 실패했습니다. 모델이 모든 것에 지나치게 민감하게 반응했고, Claude는 Fable과 Opus 사이를 계속 오갔습니다. 또한 응답 생성 과정에서 비정상적으로 많은 오류가 발생했습니다. 42건의 요청 중 27건에서 응답 오류가 발생했습니다.
중요한 차이점:
1. SKILLS가 달라졌습니다! 모든 단계에서 그런 것은 아니지만, 대다수의 경우 더 포괄적으로 바뀌었으며, 설계 시 “AI의 부주의함”을 방지하고 필요할 때 다른 SKILLS를 더 세밀하게 활용하기 위한 지침이 추가되었습니다.
2. SKILLS 코딩에는 이전 버전보다 더 많은 지침이 포함되어 있으며, 코딩 스타일에 대한 설명도 더 상세해졌습니다.
3. 프로세스 중 자체 점검이 더 많이 이루어집니다.
4. hallucination_mitigation - 개발자 프롬프트 자체와 마찬가지로 이 부분도 더 강화되었습니다. 이는 환각 현상에 대한 대응이 더욱 강력해졌으며, 개발자를 위한 에이전트 모드 작업 시 세부 사항에 더 많은 주의를 기울이고 있음을 의미합니다.
5. 모델의 응답 정확도는 향상되었으나, 모델 보안 측면에서는 오탐지(false positive) 수가 급격히 증가했습니다.