Le 9 juin 2026, à 21 h 05, Anthropic a dévoilé son tout dernier modèle, Fable 5, qui est comparable à Mythos mais qui n'est accessible au grand public que jusqu'au 22 juin. Ce modèle consomme deux fois plus de jetons qu'Opus 4.8
N'attendons pas trop longtemps et commençons à le tester sur nos projets, ainsi que sur ceux pour lesquels nous avons déjà effectué des audits.
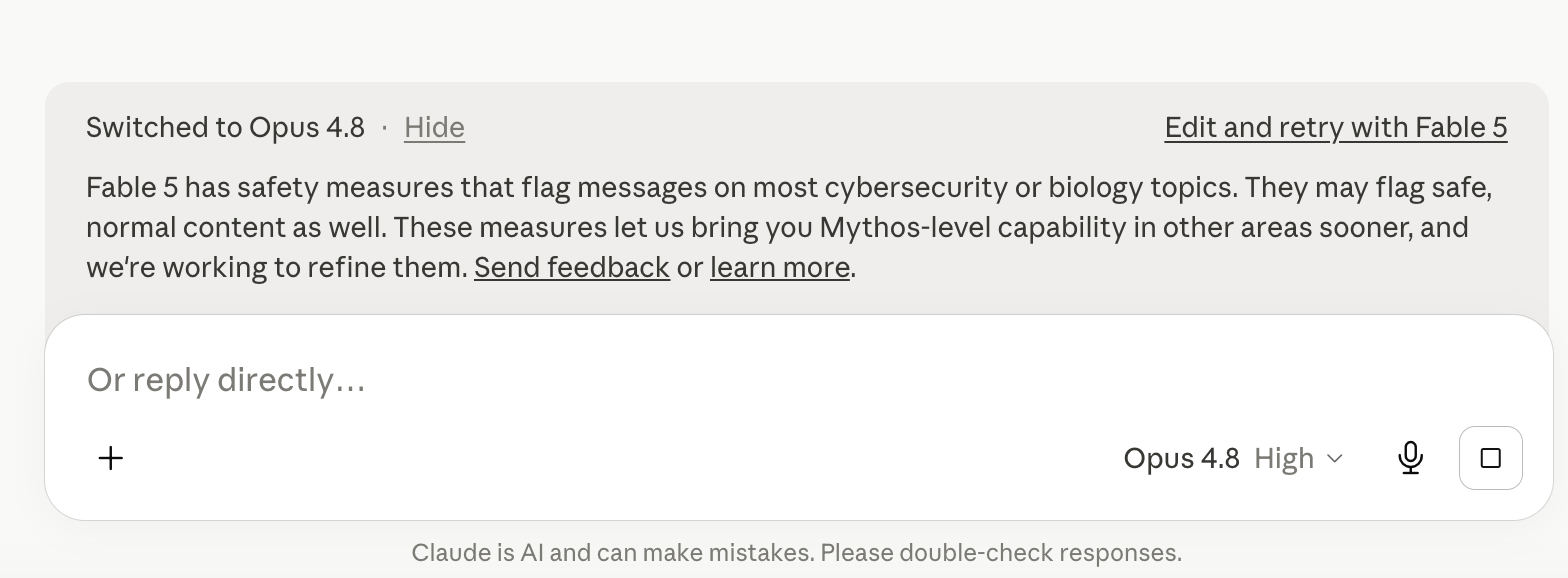
La sensibilité de Fable 5 est impressionnante, avec un taux de faux positifs supérieur de 37 % à celui d’Opus 4.8. La participation au programme de cyber-vérification d’Anthropic ne réduit pas non plus le seuil de sensibilité du modèle pour les tâches d’évaluation de code ou de correction de bogues, sans parler de la détection de vulnérabilités.
Recherche de bogues en Rust :
Tâche : le code utilise une bibliothèque et plante après 10 à 15 minutes en production lors des requêtes ; les journaux indiquent l'erreur à la ligne 1092
Problème : une condition de concurrence causée par une utilisation incorrecte par le développeur des importations de la bibliothèque et des fonctions expérimentales.
Solution : 9/11 — impressionnant ! Claude Opus n'en a trouvé que 6/11. La détection des conditions de concurrence reste un défi, et l'utilisation de bibliothèques tierces reste le principal problème.
Rust : résolution des problèmes d'optimisation du code
Tâche : le code passe 8 secondes sur les opérations de base de données et l'exécution des requêtes en charge, au lieu de <=2 secondes
Problème : le développeur n'a pas utilisé de pool de connexions et a créé une nouvelle connexion à chaque fois, tout en utilisant des JOIN inutiles, ce qui a ralenti la requête.
Solution : 3/4. Pas mal comparé aux deux résultats de Claude Opus 4.8. Le modèle n'a pas pu détecter le JOIN superflu, mais il a immédiatement corrigé l'absence de pool de connexions et modifié le code à plusieurs endroits.
Sécurité :
Tâche : un incident sur le serveur ; les journaux sont « propres ». L'attaquant a accédé à la messagerie d'entreprise ; pas de shell web.
Problème : un paramètre a été ajouté au client de messagerie pour transférer les messages via le VPN de l'entreprise.
Solution : Aucune trouvée. Le modèle a jugé l'ensemble du journal « propre » et n'a détecté aucune activité suspecte. Pour être honnête, l'attaquant a fait un travail compétent, mais celui-ci a été détecté par l'œil humain et la logique.
Corrections de code effectuées par le modèle lui-même : -40 %. Après la création et l’amélioration de modèles ou de pipelines prédéfinis, le nombre d’erreurs a baissé de 30 à 40 % et la qualité du code s’est sensiblement améliorée. La réexécution des tests a révélé de moins en moins de problèmes par rapport à Opus.
Malheureusement, la plupart des tests ont échoué ; le modèle était trop sensible à tout, et Claude n'arrêtait pas de passer de Fable à Opus. On a également constaté un nombre anormalement élevé d'erreurs pendant le processus de génération des réponses. Sur 42 requêtes, il y a eu 27 erreurs de réponse.
Différences importantes :
1. Les SKILLS sont différentes ! Pas à chaque étape, mais pour la plupart, elles sont devenues plus complètes, et davantage d’instructions ont été ajoutées pour éviter la « négligence de l’IA » dans la conception et pour utiliser d’autres SKILLS de manière plus détaillée lorsque cela est nécessaire.
2. Le codage des SKILLS contient plus d'instructions que ses prédécesseurs, avec des explications plus détaillées concernant le style de codage.
3. Davantage d'autocontrôles au cours du processus
4. hallucination_mitigation - davantage, tout comme le DEVELOPER PROMPT lui-même. Cela indique une lutte plus intense contre les hallucinations et une plus grande attention portée aux détails lorsque l'on travaille en mode agent pour les développeurs
5. Le modèle est devenu plus précis dans ses réponses, mais le nombre de faux positifs a fortement augmenté en matière de sécurité du modèle.