On June 9, 2026, at 9:05 PM, Anthropic unveiled its latest model, Fable 5, which is comparable in class to Mythos but is available only to the public and only until June 22. The model consumes twice as many tokens as Opus 4.8
Let’s not wait too long and start testing it on our projects, as well as on projects where we’ve already conducted audits.
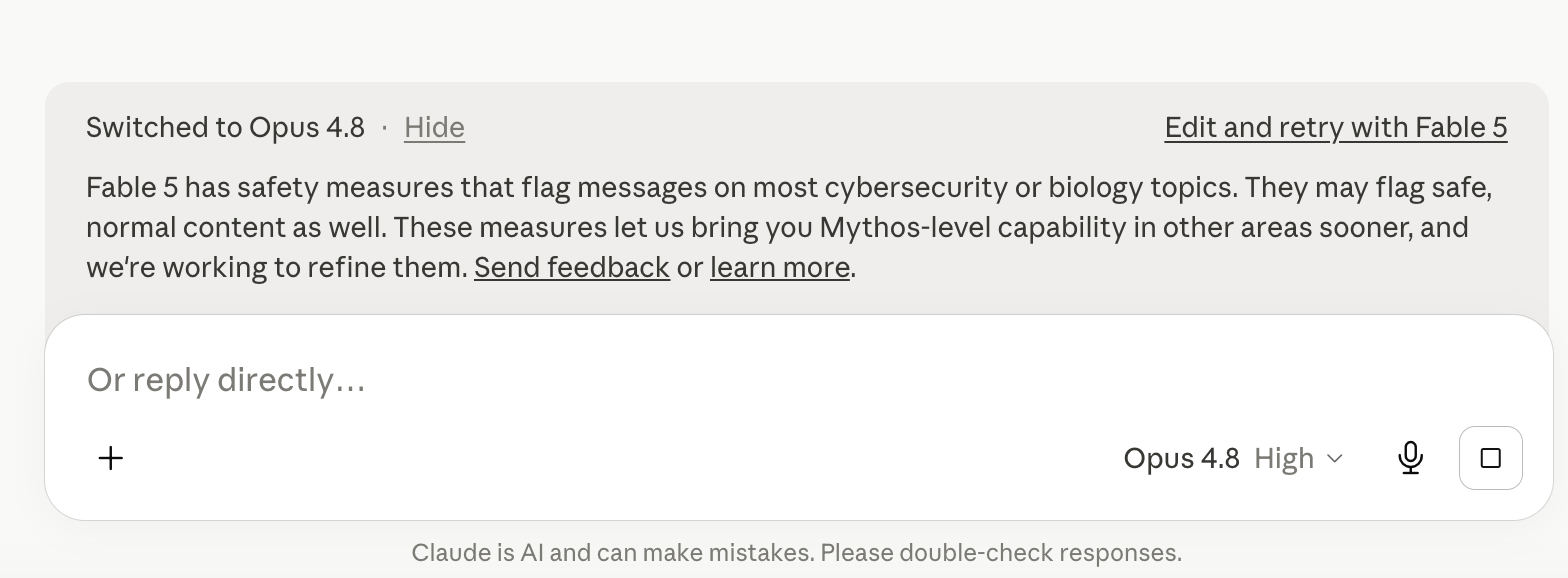
Fable 5’s sensitivity is impressive, with a 37% higher false positive rate compared to Opus 4.8. Participation in Anthropic’s Cyber Verification Program also does not lower the model’s sensitivity threshold for code evaluation or bug fixing tasks, let alone vulnerability detection.
Rust bug hunting:
Task: The code uses a library and crashes after 10–15 minutes in production during requests; the logs show the error on line 1092
Problem: A race condition caused by the developer incorrectly using imports from the library and experimental functions.
Solution: 9/11—impressive! Claude Opus found only 6/11. Finding race conditions remains a challenge, and working with third-party libraries remains the main issue.
Rust: resolving code optimization issues
Task: The code spends 8 seconds on database operations and query execution under load instead of <=2 seconds
Problem: The developer did not use a connection pool and created a new connection each time, as well as used unnecessary JOINs, which slowed down the query.
Solution: 3/4. Not bad compared to the two findings from Claude Opus 4.8. The model was unable to find the extra JOIN, but it immediately corrected the lack of a connection pool and fixed the code in several places.
Security:
Task: An incident on the server; the logs are “clean.” The attacker gained access to corporate email; no web shell.
Problem: A setting was added to the email client to forward messages via the corporate VPN.
Solution: None found. The model deemed the entire log clean and detected no suspicious activity. To be honest, the attacker did a competent job, but it was detected by the human eye and logic.
Code fixes made by the model itself: -40%. After creating and improving pre-built models or pipelines, the number of errors dropped by 30–40% and code quality improved noticeably. Rerunning the tests found fewer and fewer issues compared to Opus.
Unfortunately, most of the tests were unsuccessful; the model was too sensitive to everything, and Claude kept switching from Fable to Opus. There was also an abnormally high number of errors during the response generation process. Out of 42 requests, there were 27 response errors.
Important differences:
1. SKILLS are different! Not in every stage, but for the majority, they have become more extensive, and more instructions have been added to avoid “AI sloppiness” in the design and to utilize other SKILLS in greater detail when necessary.
2. SKILLS coding contains more instructions than its predecessors, with more detailed explanations regarding coding style.
3. More self-checks during the process
4. hallucination_mitigation - more, just like the DEVELOPER PROMPT itself. This indicates a stronger fight against hallucinations and greater attention to detail when working in agent mode for developers
5. The model has become more accurate in its responses, but the number of false positives has risen sharply in case of model security.