Am 9. Juni 2026 um 21:05 Uhr stellte Anthropic sein neuestes Modell, Fable 5, vor, das in seiner Klasse mit Mythos vergleichbar ist, jedoch nur der Öffentlichkeit zugänglich ist – und das auch nur bis zum 22. Juni. Das Modell verbraucht doppelt so viele Token wie Opus 4.8
Warten wir nicht zu lange und beginnen wir damit, es in unseren Projekten sowie in Projekten zu testen, in denen wir bereits Audits durchgeführt haben.
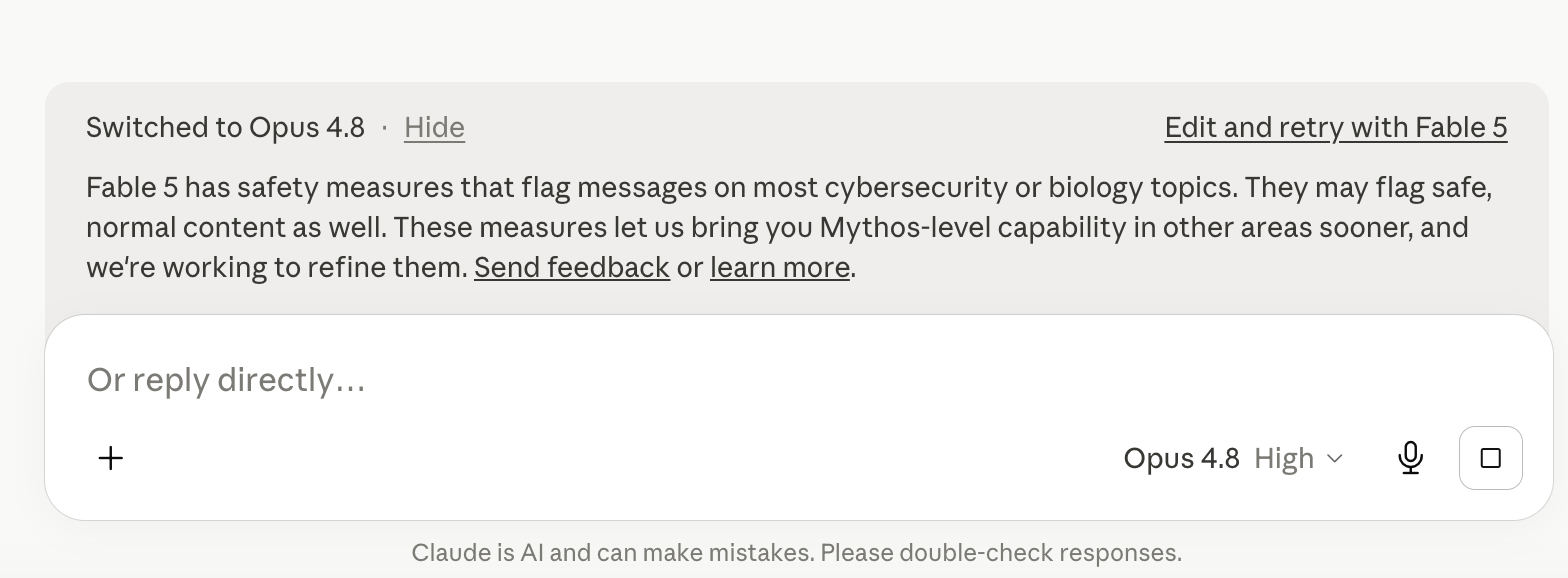
Die Sensitivität von Fable 5 ist beeindruckend, mit einer um 37 % höheren Falsch-Positiv-Rate im Vergleich zu Opus 4.8. Die Teilnahme am Cyber-Verification-Programm von Anthropic senkt zudem nicht die Sensitivitätsschwelle des Modells für Code-Evaluierung oder Bug-Fixing-Aufgaben, geschweige denn für die Erkennung von Schwachstellen.
Rust-Bug-Jagd:
Aufgabe: Der Code nutzt eine Bibliothek und stürzt nach 10–15 Minuten im Produktionsbetrieb während Anfragen ab; die Logs zeigen den Fehler in Zeile 1092
Problem: Eine Race Condition, verursacht durch die falsche Verwendung von Importen aus der Bibliothek und experimentellen Funktionen durch den Entwickler.
Lösung: 9/11 – beeindruckend! Claude Opus fand nur 6/11. Das Auffinden von Race Conditions bleibt eine Herausforderung, und die Arbeit mit Bibliotheken von Drittanbietern ist weiterhin das Hauptproblem.
Rust: Behebung von Problemen bei der Code-Optimierung
Aufgabe: Der Code benötigt unter Last 8 Sekunden für Datenbankoperationen und die Ausführung von Abfragen statt <=2 Sekunden
Problem: Der Entwickler hat keinen Verbindungspool verwendet und jedes Mal eine neue Verbindung hergestellt sowie unnötige JOINs verwendet, was die Abfrage verlangsamte.
Lösung: 3/4. Nicht schlecht im Vergleich zu den zwei Fundstellen von Claude Opus 4.8. Das Modell konnte den zusätzlichen JOIN nicht finden, korrigierte jedoch sofort das Fehlen eines Verbindungspools und reparierte den Code an mehreren Stellen.
Sicherheit:
Aufgabe: Ein Vorfall auf dem Server; die Protokolle sind „sauber“. Der Angreifer verschaffte sich Zugriff auf die Unternehmens-E-Mails; keine Web-Shell.
Problem: Im E-Mail-Client wurde eine Einstellung hinzugefügt, um Nachrichten über das Unternehmens-VPN weiterzuleiten.
Lösung: Keine gefunden. Das Modell stufte das gesamte Protokoll als sauber ein und erkannte keine verdächtigen Aktivitäten. Ehrlich gesagt hat der Angreifer seine Sache gut gemacht, aber der Vorfall wurde durch menschliches Auge und Logik entdeckt.
Vom Modell selbst vorgenommene Code-Korrekturen: -40 %. Nach der Erstellung und Verbesserung vorgefertigter Modelle oder Pipelines sank die Fehlerzahl um 30–40 % und die Codequalität verbesserte sich spürbar. Bei der erneuten Durchführung der Tests wurden im Vergleich zu Opus immer weniger Probleme gefunden.
Leider waren die meisten Tests erfolglos; das Modell reagierte auf alles zu empfindlich, und Claude wechselte ständig zwischen Fable und Opus hin und her. Außerdem gab es eine ungewöhnlich hohe Anzahl von Fehlern während des Prozesses der Antwortgenerierung. Von 42 Anfragen gab es 27 Antwortfehler.
Wichtige Unterschiede:
1. SKILLS sind anders! Nicht in jeder Phase, aber in den meisten Fällen sind sie umfangreicher geworden, und es wurden mehr Anweisungen hinzugefügt, um „AI-Nachlässigkeit“ im Design zu vermeiden und andere SKILLS bei Bedarf detaillierter zu nutzen.
2. Die SKILLS-Codierung enthält mehr Anweisungen als ihre Vorgänger, mit detaillierteren Erläuterungen zum Codierungsstil.
3. Mehr Selbstprüfungen während des Prozesses
4. hallucination_mitigation – mehr davon, genau wie beim DEVELOPER PROMPT selbst. Dies deutet auf einen stärkeren Kampf gegen Halluzinationen und eine größere Detailgenauigkeit bei der Arbeit im Agentenmodus für Entwickler hin
5. Das Modell ist in seinen Antworten präziser geworden, jedoch ist die Anzahl der Fehlalarme im Hinblick auf die Modellsicherheit stark angestiegen.